Sponsored Content by Milliman
The Evolution of Analytics

Predictive analytics are not new.
The term gained traction in recent years, riding the wave of Big Data, but actuaries have been using predictive modeling techniques such as GLMs and decision trees for at least 20 years.
Advancing technology and new data sets, however, have allowed predictive analytics to evolve in sophistication.
“What was called ‘data mining’ in the 1990s was renamed ‘analytics’ in the 2000s, and as new technologies and methods for data storage, preparation, and visualization emerged in the 2010s, this field of work has been rebranded again as ‘data science,’” said Peggy Brinkmann, Principal & Consulting Actuary, Milliman.
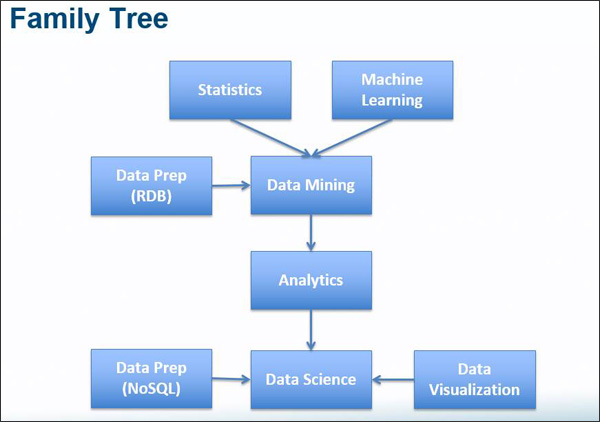
The Evolution of Analytics: Although the buzz words have changed (data mining, analytics, data science), they are all related and have built upon each other as our data, technology, and analytic methods have evolved over time.
“We’ve seen an evolution of greater granularity and richness of data, new sources of data, and more cost-effective technologies for storing, processing, and analyzing that data.”
Better tools, more data and more computing power mean that actuaries and insurers can apply predictive analytics in new ways, such as tailoring claims management approaches based on predicted outcomes, building more detailed risk assessments, and more accurately pricing risk.
Some key areas that predictive analytics are changing the way insurers do business include:
1. Claims

Peggy Brinkmann, Principal & Consulting Actuary
More sophisticated predictive tools allow earlier identification of an insurer’s most and least expensive claims.
“Identifying low cost claims early allows insurers to perhaps reduce the resources that would typically be dedicated to that claim. Those extra resources can then be re-directed to high cost claims,” said Philip Borba, Principal, Economics Consulting, Milliman.
Borba uses machine learning techniques that starts with a long list of characteristics and then proceeds to identify the characteristics that have the greatest influence on distinguishing claim costs, recovery opportunities, and other claim-management outcomes. These machine learning techniques often end with a “claim score,” not unlike scores used in other industries. Also, some of the characteristics are coming from data that were underused in the past. Text-mining allow insurers to dig deeper into claims data to glean new and valuable information from existing data sources — primarily, medical reports and adjusters’ notes.
Those notes contain clues that indicate whether a claim is likely to be high or low cost.
“Historically, you wouldn’t know that a surgery was involved in a claim until you got the bill for it six weeks later. But the adjusters probably talked about the possibility of surgery in the first few days after the claim occurred,” Borba said. “We now have the software to go through the adjusters’ notes and pick out these clues that indicate that this may be a serious, high cost claim.
Fifteen to 20 years ago, the computing power did not exist to efficiently comb text for key words or patterns. It was all done manually — a time-consuming endeavor. More powerful computers and text mining software solutions mean that actuaries can categorize and predict potential claim outcomes as early as 30 days in.
“This is a bit of a sea change, because we’re no longer looking at claims that are five to 10 years old and retroactively making the connection that those involving surgeries or attorneys were high cost claims,” Borba said.
“Now we can do that within a month, but using different data.”
2. Driving Safety

Philip Borba, Principal, Economics Consulting
Vehicle telematics provide detailed insight into the specific drivers or driving behaviors that contribute to losses. As auto claims costs skyrocket, tightening up loss prevention is a major focus for fleet managers.
Some individuals and fleets opt to install telematics devices directly into their vehicles, but those units are costly. Another popular option is to have drivers download a smartphone app that can decipher if and when the driver uses his phone while on the road.
“The app won’t monitor who you’re calling or texting, what you’re saying, or what other apps you may be using, but it can determine when the phone is in use,” Brinkmann said.
That data is invaluable as distracted driving increasingly contributes to accidents.
“We’re continuously using machine learning to process this data and benchmark our models, and to help us identify the weak points in the generalized linear models we use for auto risks,” Brinkmann said. “For pricing applications, you don’t necessarily see the machine learning in the final model, but we’ve used it in the background to adjust the model to be as predictive of loss as possible.”
Data collected via telematics can actually replace traditional auto underwriting variables, like age, gender, and garaging location.
“Not everyone in each of those groups has the same risk. By collecting more data on drivers, we can go deeper and find the points of differentiation in their risk profiles,” Brinkmann said. “The more data we accumulate, the more granular we can get.”
3. Property Risk
Data and machine learning can provide similar granularity on property risk — specifically, susceptibility to natural catastrophe like flood or hurricane.
“We can look at specific latitudes and longitudes, relative elevation and distance from a river or coast. For hurricanes, we can look at information about land cover, because surface roughness affects your hurricane risk,” Brinkmann said. “The likelihood that your property will be damaged by a sinkhole depends on variables like the soil permeability, population density, and ground water level of the location.”
That level of detail in geological and geographic information did not exist in the past. A more specific and individualized view of risk lends itself to more tailored underwriting and more accurate risk pricing.
4. Competitive Rating
Risk pricing that is more closely tied to loss experience also gives insurance carriers a clearer view into their competitive standing in a given market.
“When you propose redoing rates for a company to better reflect their cost of risk, their first question is usually, ‘How does this impact my competitive standing?’” Brinkmann said.
Working with comparative rating engine vendors, Milliman can show clients how their rates stack up against competitors within their market segment. Clients can access the data themselves to see how a change in their competitive positioning impacts a particular book of business. Or if they want to enter a new market or launch a new program, for example, they can see what the average rates are and whether it could be a profitable market for them.
“That allows you to either get rid of risks that were badly priced or adversely select risks against your competitors that you can write at a more competitive rate,” Brinkmann said. “I call it descriptive analytics. I’m not predicting what their outcome will be, but the data the analysis enabled by machine learning helps them sift through all of this information and identify these segment definitions that are useful to their business.”
“There’s nothing like having solid data to guide your decision.”
To learn more, visit http://us.milliman.com/us/solutions/analytics/.
![]()
This article was produced by the R&I Brand Studio, a unit of the advertising department of Risk & Insurance, in collaboration with Milliman. The editorial staff of Risk & Insurance had no role in its preparation.









